
Автор: Евгений Бодягин, https://dsprog.pro
В данном материале рассмотрим объявления автомобилей с целью перепродажи (позиция брокера). Возникают вопросы:
- Популярность брендов и марок автомобилей — какова ситуация на рынке?
- Как можно выявлять отдельные «недооцененные» объявления?
- Насколько они недооценены?
- Какую наценку брокер может устанавливать при перепродаже?
- Какая стратегия возможна?
- Возможно ли получить какие то данные объем рынка перепродажи?
Вопросов много, давайте разбираться.
Отмечу также, что применяемый здесь подход в целом применим не только к автомобилям, но и к объектам недвижимости, оборудованию и проч. Данные о продаже автомобилей были получены парсингом с сайта одной из зарубежных интернет-площадок.
Для анализа будем использовать элементы корреляционного анализа и Random Forest.
Данная статья ни в коем случае не претендует на то, что объем расчетов который здесь демонстрируется необходим и достаточен. Здесь дана верхушка айсберга 😉
Структура данных
- Марка (Make): Марка автомобиля.
- Модель (Model): Модель автомобиля.
- Год (Year): Год выпуска автомобиля.
- Тип топлива двигателя (Engine Fuel Type): Тип топлива, которое используется для двигателя.
- Мощность двигателя (Engine HP): Мощность двигателя автомобиля в лошадиных силах.
- Количество цилиндров двигателя (Engine Cylinders): Количество цилиндров в двигателе автомобиля.
- Тип трансмиссии (Transmission Type): Тип трансмиссии (коробки передач).
- Привод (Driven_Wheels): Тип привода автомобиля, например, «front wheel drive» (передний привод).
- Количество дверей (Number of Doors): Количество дверей у автомобиля.
- Рыночная категория (Market Category): Категория автомобиля на рынке.
- Размер автомобиля (Vehicle Size): Размер автомобиля.
- Стиль автомобиля (Vehicle Style): Стиль автомобиля.
- Потребление топлива на шоссе (Highway MPG): Расход топлива на шоссе в милях на галлон топлива.
- Потребление топлива в городе (City MPG): Расход топлива в городе в милях на галлон топлива.
- Популярность (Popularity): Индекс популярности автомобиля, основанный на его количестве продаж или спросе на рынке.
- Рекомендуемая розничная цена (MSRP): Рекомендуемая розничная цена автомобиля.
Загрузка необходимых пакетов
import sklearn import sys from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import cross_val_score from sklearn.preprocessing import LabelEncoder import csv import numpy as np import pandas as pd import plotly.express as px import plotly.graph_objects as go from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report
Загрузка данных
full_data = pd.read_csv("input/data.csv")
headers = full_data.columns.tolist()
# Выведем заголовки датасета
print(headers)
[‘Make’, ‘Model’, ‘Year’, ‘Engine Fuel Type’, ‘Engine HP’, ‘Engine Cylinders’, ‘Transmission Type’, ‘Driven_Wheels’, ‘Number of Doors’, ‘Market Category’, ‘Vehicle Size’, ‘Vehicle Style’, ‘highway MPG’, ‘city mpg’, ‘Popularity’, ‘MSRP’]
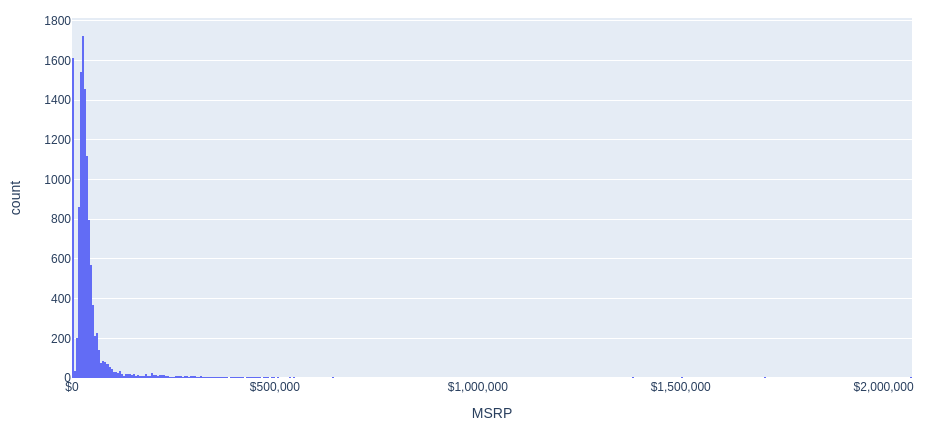
Гистограмма распределения цен (MSRP)
Построим гистограмму распределения цен на автомобили.
fig = px.histogram(full_data, x='MSRP', nbins=500)
fig.update_layout(
width=1000,
height=500,
xaxis=dict(
tickformat='$,.0f',
ticktext=full_data['MSRP'].map(lambda x: '${:,.0f}'.format(x))
)
)
fig.show()
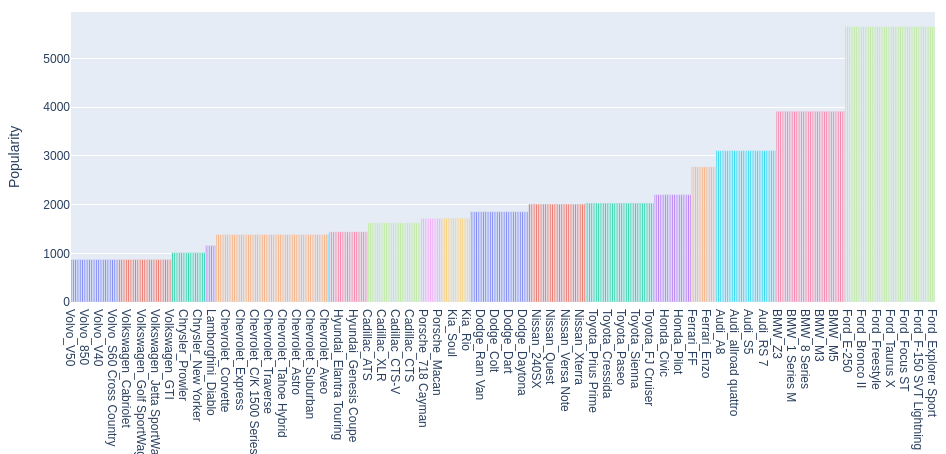
Популярность брендов и марок автомобилей
Построим диаграмму популярности комбинаций Make, Model.
# Сформируем отдельный датасет 'cars_popularity':
cars_popularity = pd.DataFrame()
cars_popularity['Make'] = full_data['Make']
cars_popularity['Model'] = full_data['Model']
cars_popularity['Popularity'] = full_data['Popularity']
# Объединим 'Make', 'Model' в единый показатель 'Make_Model':
cars_popularity['Make_Model'] = cars_popularity['Make'] + '_' + cars_popularity['Model']
# Удалим дубликаты:
cars_popularity = cars_popularity.drop_duplicates(subset=['Make_Model'])
# Данных слишком много для отображеения диаграмы по популярности.
# this content is from dsprog.pro
# Для того, чтобы выделить самые популярные типы автомобилей относительно медианного значения Popularity:
median_popularity = cars_popularity['Popularity'].median()
cars_popularity = cars_popularity[cars_popularity['Popularity'] >= median_popularity]
# Отсортируем DataFrame по столбцу Popularity:
cars_popularity = cars_popularity.sort_values(by='Popularity')
# Создаем столбчатую диаграмму с использованием plotly:
#fig = px.bar(cars_popularity, x='Make_Model', y='Popularity', title='Popularity by Make and Model',
fig = px.bar(cars_popularity, x='Make_Model', y='Popularity', title='Популярность брендов и марок автомобилей',
color='Make', height=600, width=1024)
fig.update_layout(showlegend=False)
fig.show()
Элементы корреляционного анализа
Процедура поиска объявлений с заниженной ценой базируется на показателях/характеристиках.
Но… все ли они нужны нам? Желательно оперировать сильными (информативными) показателями. Тогда классификационная модель Random Forest будет иметь хорошие качества. Об информативности может свидетельствовать корреляция, чье абсолютное значение будет выше определенного порогового значения.
Определим данный порог равным 0.25
Если корреляция между рассматриваемым показателем меньше -0.25 либо больше чем +0.25 будем считать, что потенциально данный показатель будет сильным в модели Random Forest. Если же значение корреляции будет находиться а диапазоне (-0.25 ; +0.25) — отфильтровываем / не рассматриваем текущий показатель/характеристику автомобиля.
Ввиду того, что показатели имеют разнородный характер, в качестве меры корреляции будем использовать непараметрический критерий Спирмена. Оговоримся, что данная техника требует дополнительных обработок.
Дабы не увеличивать объем данной статьи, ограничимся упрощенным вариантом расчетов.
# Удаляем битые строки в датасете
full_data = full_data.dropna()
# Сохраним показатели Make и Model в отдельные датафреймы, они нам еще пригодятся ;)
Xmake = full_data['Make']
Xmodel = full_data['Model']
# Кодирование категориальных переменных
encoder = LabelEncoder()
categorical_columns = ['Make', 'Model', 'Engine Fuel Type', 'Transmission Type', 'Driven_Wheels',
'Market Category', 'Vehicle Size', 'Vehicle Style']
for col in categorical_columns:
# this content is from dsprog.pro
full_data[col] = encoder.fit_transform(full_data[col])
# Расчет корреляции Спирмена по всем столбцам/показателям
full_corr = full_data.corr(method='spearman')
# Создаем тепловую карту корреляций
fig = go.Figure(data=go.Heatmap(
z=full_corr.values,
x=full_corr.columns,
y=full_corr.columns,
colorscale='RdBu'))
fig.update_layout(
title='Correlation between MSRP and other variables',
width=800,
height=700
)
fig.show()
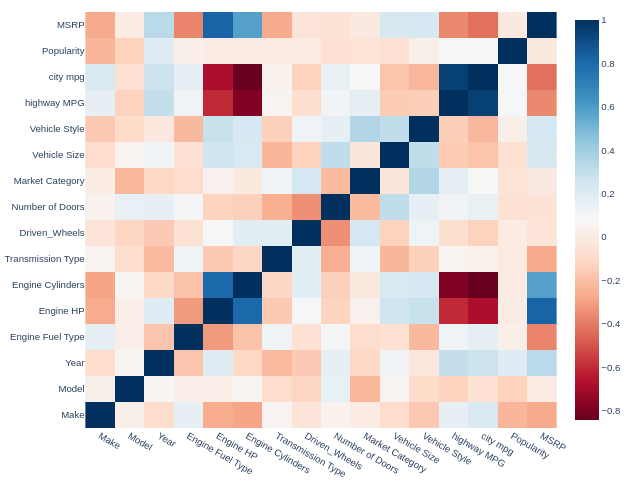
Нас интересует самая верхняя строка (MSRP). Интересны корреляции с насыщенным цветом. Настало время отсеять потенциально слабые показатели!
threshold = 0.25
columns_to_exclude = full_corr.columns[(full_corr['MSRP'] < threshold) & (full_corr['MSRP'] > -threshold)].tolist()
print("Потенциально слабые показатели/характеристики, корреляция Спирмена которых находится в диапазоне от -{} до +{} с MSRP:".format(threshold, threshold))
print(columns_to_exclude)
columns_to_exclude.remove('Model')
print("Показатель 'Model' оставим его с потенциально сильными.")
print("Откорректируем перечень с учетом данного нюанса.")
print("Потенциально слабые показатели/характеристики, корреляция Спирмена которых находится в диапазоне от -{} до +{} с MSRP:".format(threshold, threshold))
print(columns_to_exclude)
Потенциально слабые показатели/характеристики, корреляция Спирмена которых находится в диапазоне от -0.25 до +0.25 с MSRP: [‘Model’, ‘Driven_Wheels’, ‘Number of Doors’, ‘Market Category’, ‘Vehicle Size’, ‘Vehicle Style’, ‘Popularity’]
Показатель ‘Model’ оставим его с потенциально сильными. Откорректируем перечень с учетом данного нюанса.
Потенциально слабые показатели/характеристики, корреляция Спирмена которых находится в диапазоне от -0.25 до +0.25 с MSRP: [‘Driven_Wheels’, ‘Number of Doors’, ‘Market Category’, ‘Vehicle Size’, ‘Vehicle Style’, ‘Popularity’]
Удалим потенциально слабые показатели.
for column in columns_to_exclude:
full_data = full_data.drop(column, axis=1)
Функция предобработки
Для разделения выборки данных на датасет объясняющих и объясняемой переменных напишем соответствующую функцию.
def GetDataForProcessing(full_data, Xmodel, Xmake):
X = pd.DataFrame()
Y = pd.DataFrame()
#
X = full_data.drop('MSRP', axis = 1)
Y = full_data['MSRP']
# Преобразование кодирования One-Hot; значения NaN не должны быть включены в dummy-переменные
string_columns = X.select_dtypes(include=['object']).columns.tolist()
# this content is from dsprog.pro
# Преобразуем столбцы в дамми-переменные
X = pd.get_dummies(X, dummy_na=False, columns=string_columns)
# Вот и пригодились текстовые данные о брэнде и модели ;)
X.insert(0, 'ModelRef', Xmodel);
X.insert(0, 'MakeRef', Xmake);
X.fillna(0, inplace=True);
return (X, Y)
Загрузка данных
Получим датасеты объясняющих и объясняемой переменных.
(X, Y) = GetDataForProcessing(full_data, Xmodel, Xmake)
Построение прогнозной модели случайного леса
Пришло время для запуска Random Forest!
# Преобразуем датафрейм Y в одномерный массив:
Y_unraveled = np.ravel(Y);
# Разделим набор данных на обучающую часть и часть для тестирования:
print('Splitting into training and testing...')
# this content is from dsprog.pro
X_train, X_test, Y_train, y_test = train_test_split(X, Y_unraveled, test_size=0.10, random_state=14)
# Удалим столбцы бренда и модели в полученных выборках; это необходимо для того чтобы отправить данные в Random Forest:
X_train2 = X_train.drop('MakeRef', axis = 1).drop('ModelRef', axis = 1)
X_test2 = X_test.drop('MakeRef', axis = 1).drop('ModelRef', axis = 1)
# Определим количество деревьев в ансамбле:
nEstimators = 500
# Start building Random Forest
# this content is from dsprog.pro
print('Start processing...')
clf = RandomForestRegressor(n_estimators=nEstimators, max_features="sqrt");
# # Обучим модель RandomForestRegressor на данных X_train2 и Y_train.
clf = clf.fit(X_train2, Y_train);
print("Processing completed.")
print('Calculating error...')
# Применим обученную модель к тестовым данным для предсказания целевой переменной.
y_pred = clf.predict(X_test2);
# Вычислим оценки кросс-валидации для модели с количеством частей (фолдов) равным 5
scores = cross_val_score(clf,X_test2,y_test, cv = 5)
# В качестве метрики оценки производительности для scores является коэффициент детерминации (R-квадрат).
print("Scores:")
print(scores);
print("Mean absolute error:");
mean_error = sum(abs(y_test-y_pred))/len(y_test);
print(mean_error);
print("Mean percent error: ")
print(mean_error/np.mean(y_test))
Splitting into training and testing…
Start processing…
Processing completed.
Calculating error…
Scores:
[0.86870384 0.89972474 0.95399538 0.81898592 0.8892757 ]
Mean absolute error:
3940.0326236912783
Mean percent error:
0.0808909095731506
Полученная модель имеет довольно неплохие результаты. В пяти фолдах из пяти имеем оценки большие чем 0.81!
Средняя точность текущей модели получил оценку 0.886 из возможных 1.0
Это говорит о том, что моделью можно и нужно пользоваться, но не стоит забывать про здравый смысл и эмпирический опыт 😉
Отмечу также, что без отсева потенциально слабых показателей два фолда из пяти давали бы оценку всего лишь около 0.3!
Техника отсева потенциально слабых показателей с помощью корреляции Спирмена успешно работает 😉
Влияние характеристик автомобилей на цену
Отсортируем показатели/характеристики автомобилей по их влиянию на цену (MSRP) в рамках полученной модели Random Forest.
importances = clf.feature_importances_
print(importances)
std = np.std([tree.feature_importances_ for tree in clf.estimators_],axis=0)
indices = np.argsort(importances)[::-1]
features = X_test2.columns.values
topLimit = 20
indices = indices[0: topLimit] #
topLabels = features[indices[0: topLimit]]
# this content is from dsprog.pro
figsize = (12, 6)
fig = go.Figure(data=[go.Bar(x=topLabels, y=importances[indices], error_y=dict(type='data', array=std[indices]), marker_color='red')],
layout=go.Layout(
width=figsize[0] * 80,
height=figsize[1] * 80,
title="Top 20 Important Features",
xaxis=dict(tickangle=45),
yaxis=dict(title='Importance')
))
fig.show()
[0.04590761 0.07747029 0.04278068 0.02700366 0.35806064 0.24427857 0.01798086 0.05793945 0.12857824]
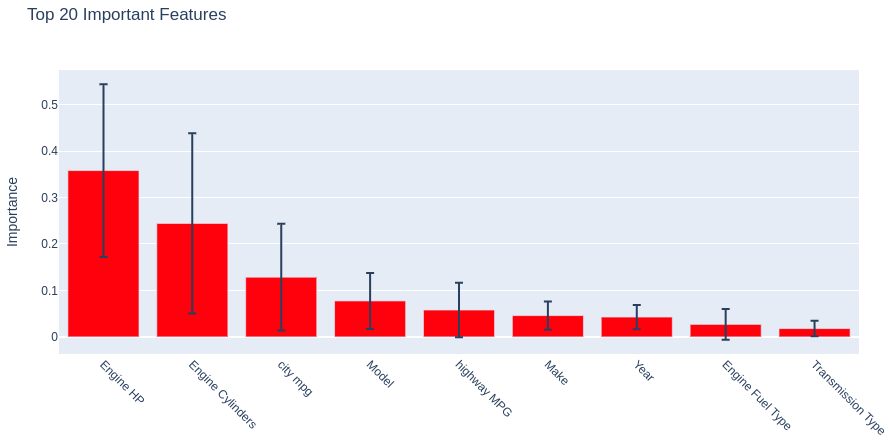
Первые три позиции:
1) Мощность двигателя (Engine HP);
2) Количество цилиндров двигателя (Engine Cylinders);
3) Потребление топлива в городе (City MPG)
занимают те самые показатели, которые имели большие значения корреляции Спирмена.
Определение выборки потенциально интересных автомобилей
Вернемся к вопросу. Как выявлять «недооцененные» объявления и… причем здесь Random Forest?
Ответ в следующем: фактически модель воспринимается нами в качестве эксперта. Когда мнение эксперта (прогноз) о цене объявления не совпадает с фактической ценой (факт) это означает, что либо:
- цена завышена (факт больше прогноза);
- цена занижена (прогноз больше факта).
Разделим всю выборку объявлений автомобилей на область заниженных и завышенных цен.
y_diff = y_test-y_pred
df_y_diff = pd.DataFrame(y_diff, columns = ['diff'])
# Divide the column into positive and negative values
# this content is from dsprog.pro
# Dataset of ads with inflated prices:
positive_df = df_y_diff[df_y_diff['diff'] > 0]
# Dataset of ads with reduced prices:
negative_df = df_y_diff[df_y_diff['diff'] < 0]
len_positive_df = len(positive_df)
len_negative_df = len(negative_df)
rate_positive_df = round(len_positive_df / (len_positive_df + len_negative_df),2)
rate_negative_df = round(len_negative_df / (len_positive_df + len_negative_df),2)
print("========= Количество объявлений с завышенными ценами: ========")
print(len_positive_df)
print("========= Доля объявлений с завышенными ценами: ========")
print(rate_positive_df)
print("========= Количество объявлений с заниженными ценами: ========")
print(len_negative_df)
print("========= Доля объявлений с заниженными ценами: ========")
print(rate_negative_df)
========= Number of ads with inflated prices: ========
355
========= Share of ads with inflated prices: ========
0.44
========= Number of advertisements with underestimated prices: ========
445
========= Share of advertisements with underestimated prices: ========
0.56
Полагаясь на мнение эксперта (модели): доля объявлений с завышенными ценами сопоставимо с долей объявлений с заниженными ценами.
Рассмотрим области завышенных и заниженных цен с использованием гистограмм. Также определим квантили распределений. Для этого напишем соответствующую функцию.
def generate_distribution(positive_df, negative_df):
# Определим значения квантилей
positive_quantiles = positive_df['diff'].quantile([0.25, 0.5, 0.75])
negative_quantiles = negative_df['diff'].quantile([0.25, 0.5, 0.75])
# Создадим гистограмму для положительных значений с отметкой квантилей:
fig_positive = go.Figure()
fig_positive.add_trace(go.Histogram(x=positive_df['diff'], marker=dict(color='blue')))
for q in positive_quantiles:
fig_positive.add_vline(x=q, line=dict(color='red', width=3))
fig_positive.update_layout(title_text='Гистограмма положительных значений <br>(переоцененные автомобили)')
# Создайте гистограмму для отрицательных значений с отметкой квартилей
fig_negative = go.Figure()
fig_negative.add_trace(go.Histogram(x=negative_df['diff'], marker=dict(color='blue')))
for q in negative_quantiles:
fig_negative.add_vline(x=q, line=dict(color='red', width=3))
fig_negative.update_layout(title_text='Гистограмма отрицательных значений <br>(недооцененные автомобили)')
# Отобразите гистограммы
fig_positive.show()
fig_negative.show()
# Вернем значения квантилей, они нам пригодятся
# this content is from dsprog.pro
return [positive_quantiles, negative_quantiles]
quantiles = generate_distribution(positive_df, negative_df)
print("====== quantiles ======")
print(quantiles[0])
print(quantiles[1])
price_ask = round(quantiles[0][0.25], 2)
price_bid = round(quantiles[1][0.25], 2)
print("====== Price levels ======")
print("Price ask: %s: "%price_ask)
print("Price bid: %s: "%price_bid)
Гистограмма положительных значений (переоцененные автомобили)
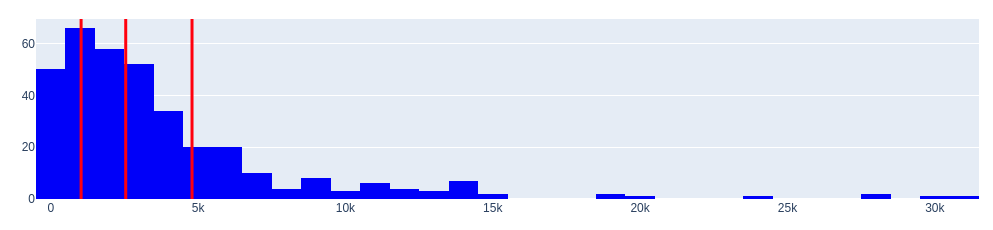
Гистограмма отрицательных значений (недооцененные автомобили)
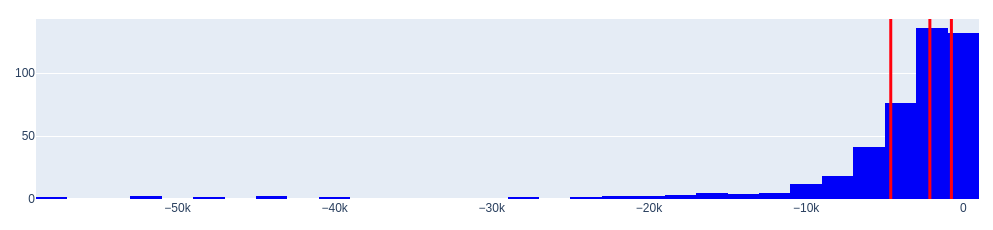
====== quantiles ======
0.25 1030.600595
0.50 2544.584000
0.75 4794.381437
Name: diff, dtype: float64
0.25 -4614.756323
0.50 -2126.003333
0.75 -756.073929
Name: diff, dtype: float64
====== Price levels ======
Price ask: 1030.6:
Price bid: -4614.76:
Гистограммы распределений говорят об одной важной особенности. Распределения имеют большие «хвосты».
Откуда они появились? Их не так уж много, но они есть.
- Во-первых, такой «хвост» может возникнуть, когда присутствуют слишком большие отклонения (выбросы) между мнением эксперта (модели Random Forest) и фактическими данными. Вспомним также, что точность полученной модели составляет в среднем 0.886 но это не 1.0
- Во вторых, причиной существования «хвостов» могут быть luxury (необычные) автомобили, когда цена имеет большое абсолютное значение.
В целом же, по выборке, мнение эксперта вполне адекватно. Как же быть?
Одно из решений — применить отсечение выбросов с помощью квантилей.
Другими словами, если эксперт выдает слишком экстравагантное мнение о заниженной стоимости, будем считать, что стоимость может быть максимально занижена продавцом лишь примерно на 4614 долларов. Итак, получен ответ на следующий вопрос поставленный здесь в самом начале!
Для выборки переоцененных автомобилей будем считать, что максимальное завышение может быть лишь примерно на 4794 доллара.
Какую наценку брокер может устанавливать при перепродаже?
Применим следующую, максимально простую стратегию. Рассмотрим те объявления, где по мнению нашего эксперта (модели) недооцененность автомобилей оценивается от 0 до 4614 долларов. Эм… однако, если ставить целью именно перепродажу, необходимо учитывать транзакционные издержки при проведении сделки. Рассмотрим такой диапазон, где недооцененность составляет от 50 долларов до 4614 долларов.
Размер недооцененности и будет величиной наценки при перепродаже. Для каждого отдельного автомобиля она будет разной.
Введем дополнительное ограничение на абсолютную цену автомобиля. Будем рассматривать лишь те объявления, абсолютное значение цены в которых превышает 5000 долларов.
Используя полученную модель можно придумать и иные стратегии. Но, на мой взгляд, данная стратегия будет способствовать скорости оборота при перепродаже.
Если просуммировать недооцененность по всем автомобилям, которые присутствуют в данном диапазоне, можно приблизительно определить объем рынка перепродажи для тестовой выборки.
Дополнительно можно получить данные об автомобилях которые переоценены, но не достаточно сильно. Вероятно, они вскоре будут проданы (эти автомобили уйдут с рынка).
Еще раз повторюсь. Здесь демонстрируется лишь верхушка айсберга. Существуют дополнительные инструменты для повышения качества модели. Полный анализ требует дополнительных расчетов и учета дополнительных нюансов. Вот один из них. Если внимательно сопоставить значение квантилей обоих выборок (с завышенными и заниженными ценами) можно увидеть, что они немного смещены вправо. Ориентировочно на значение от 200 долларов до 400 долларов. Почему? Вероятно в целом продавцы готовы поторговаться с покупателями и скинуть несколько сотен баксов, если сделка состоится 😉 Да, этот факт не привносит кардинальных изменений в выводах, но он существует.
Итак, напишем функцию которая осуществляет срез данных.
def generate_modelmakelist(direction, y_diff, price_level, transaction_level=50, price_abs=5000):
if direction == 'high':
old_indices = np.argsort(y_diff)[::-1]
head = "Автомобили, которые уйдут с рынка в течение короткого срока"
else:
old_indices = np.argsort(y_diff)
head = "Автомобили, которые интерсны с точки зрения перепродажи"
len_old_indices = len(old_indices)
modelmakelist = []
for i in range(0, len_old_indices):
# this content is from dsprog.pro
if (y_diff[old_indices[i]]!=0):
if direction == 'high':
if (0 <= y_diff[old_indices[i]] <= price_ask) & (price_abs < y_test[old_indices[i]]):
modelmakelist.append([X_test['MakeRef'].iloc[old_indices[i]] + " " + X_test['ModelRef'].iloc[old_indices[i]] + " " + str(X['Year'].iloc[old_indices[i]]), round(y_test[old_indices[i]],2),round(y_diff[old_indices[i]],2)])
else:
if (price_bid <= y_diff[old_indices[i]] <=(-transaction_level)) & (price_abs < y_test[old_indices[i]]):
modelmakelist.append([X_test['MakeRef'].iloc[old_indices[i]] + " " + X_test['ModelRef'].iloc[old_indices[i]] + " " + str(X['Year'].iloc[old_indices[i]]), round(y_test[old_indices[i]],2),round(y_diff[old_indices[i]],2)])
df_modelmakelist = pd.DataFrame(modelmakelist, columns=['Make_Model_Year', 'MSRP', 'Diff'])
x = np.arange(len(df_modelmakelist['Make_Model_Year']))
fig = go.Figure(data=[go.Bar(
x=None,
y=df_modelmakelist['Diff'],
marker_color='steelblue'
)])
fig.update_layout(
xaxis=dict(
tickmode='array',
tickvals=x,
ticktext=['']*len(x),
title='Make_Model_Year'
),
title=head,
width=1100,
height=600,
yaxis=dict(title='Diff')
)
fig.show()
return df_modelmakelist
# Построим диаграмму; сформируем список объявлений автомобилей, которые незначительно переоценены; сохраним список в файл.
df_inflated_prices = generate_modelmakelist('high', y_diff, price_ask)
df_inflated_prices.to_csv('slice_inflated_prices.csv', index=False)
# Построим диаграмму; сформируем список объявлений автомобилей, которые недооценены; сохраним список в файл.
df_underestimated_prices = generate_modelmakelist('low', y_diff, price_bid)
df_underestimated_prices.to_csv('slice_underestimated_prices.csv', index=False)
# this content is from dsprog.pro
volume_of_revenue_from_car_resale = float(-round(df_underestimated_prices["Diff"].sum(), 2))
price_of_all_advertisements = float(round(df_underestimated_prices["MSRP"].sum(), 2))
broker_commission_rate = round((volume_of_revenue_from_car_resale / (volume_of_revenue_from_car_resale + price_of_all_advertisements)), 3)
print("========= Потенциальный объем выручки от перепродажи автомобилей, которые недооценены для тестовой выборки =========")
print(volume_of_revenue_from_car_resale)
print("========= Стоимость всех автомобилей, которые недооценены на текущий момент для тестовой выборки =========")
print(price_of_all_advertisements)
print("========= Доля выручки брокера =========")
print(broker_commission_rate)
Автомобили, которые уйдут с рынка в течение короткого срока
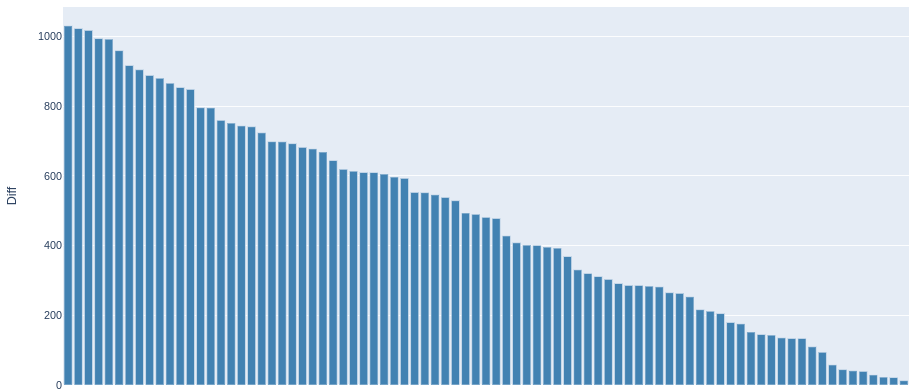
Автомобили, которые интересны с точки зрения перепродажи
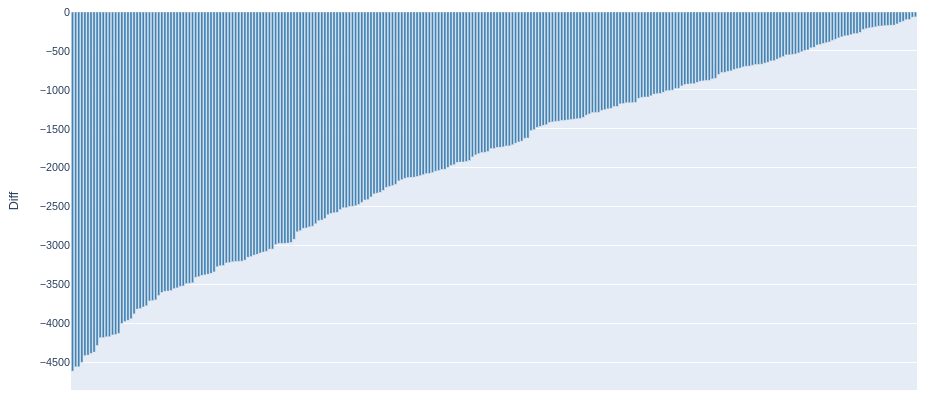
==== Потенциальный объем выручки от перепродажи автомобилей, которые недооценены для тестовой выборки =====
527804.85
========= Стоимость всех автомобилей, которые недооценены на текущий момент для тестовой выборки =========
9627616.0
========= Доля выручки брокера =========
0.052
Выводы
В данном материале рассмотрен датасет объявлений автомобилей с целью их дальнейшей перепродажи брокером.
Были получены ответы на вопросы:
- Популярность брендов и марок автомобилей — какова ситуация на рынке?
- Как можно выявлять отдельные «недооцененные» объявления?
- Насколько они недооценены?
- Какую наценку брокер может устанавливать при перепродаже?
- Какая стратегия возможна?
- Возможно ли получить какие то данные объем рынка перепродажи?
Были обработаны данные: по популярности отдельных видов автомобилей, по виду распределения цен.
С целью повышения качества классификационной модели типа Random Forest применены элементы корреляционного анализа (корреляции Спирмена). Были выявлены потенциально слабо информативные показатели и отсеяны.
Для применения Random Forest исходная выборка была разбита на датасеты объясняющих и объясняемой переменных.
Была построена модель Random Forest с количеством деревьев в ансамбле равным 500. Полученная модель имеет довольно неплохие результаты. В пяти фолдах из пяти имеем оценки большие чем 0.81
Без отсева потенциально слабых показателей два фолда из пяти давали бы оценку всего лишь около 0.3
Техника отсева потенциально слабых показателей с помощью корреляции Спирмена была успешно реализована.
Средняя точность текущей модели получил оценку 0.886 из возможных 1.0
Показатели/характеристики автомобилей были отсортированы по их влиянию на цену (MSRP) в рамках полученной модели Random Forest. Сформирована диаграмма.
Доля объявлений с завышенными ценами сопоставимо с долей объявлений с заниженными ценами. По обоим выборках сформированы гистограммы. Определены квантили распределений.
По гистограммам распределений была выявлена особенность: распределения разниц между фактическими ценами в объявлениях и суждениями эксперта (модели Random Forest) имеют большие «хвосты». Было дано объяснение их возникновения.
В качестве дополнительной меры увеличения эффективности модели было предложено применение отсечение выбросов с помощью квантилей.
Были даны рекомендации:
- по применению, максимально простой стратегии по перепродаже автомобилей с учетом полученной модели Random Forest;
- по допустимым ценовым диапазонам при применении брокером полученной модели.
Построена диаграмма; сформирован список объявлений автомобилей, которые незначительно переоценены; сохранен данный список в файл.
Построена диаграмма; сформирован список объявлений автомобилей, которые недооценены; сохранен данный список в файл.
Приблизительно определен объем выручки от перепродажи автомобилей для тестовой выборки. Он составил 527 804.85 долларов
Данная величина сформирована с учетом продемонстрированной здесь стратегии. Сделан акцент на том, что стратегии могут быть и иного вида.
Суммарная стоимость автомобилей в тестовой выборке определена как 9 627 616 долларов.
Тестовая выборка составила 10% от общей выборки объявлений.
Доля выручки брокера к обороту может составить 5.2%, что сопоставимо с размерами банковских комиссий.


